Finding C and C++ Security Vulnerabilities in PyPI with Dilligencer
Software composition analysis, like most information retrieval tasks, can be tough in the real world. There are many reasons why SCA tools fail to identify components or generate false positives. We’ve covered the pros and cons of SCA generally, as well as specific reasons why SCA often fails in prior posts.
As we discussed in those posts, one of the most common reasons for poor performance is “cross-language” dependencies. For example, we’ve highlighted the existence of Java components in Python’s PyPI package repository – like log4j or Spring JARs. While there are thousands of Python packages using Java, this kind of cross-language occurs even more frequently in Python with C and C++.
Motivated by Snyk’s recent post on the topic, we thought we’d demonstrate how to scan these C and C++ dependencies for security vulnerabilities using our Dilligencer platform. It’s a great opportunity to peel back the onion and show how efficient research and compliance tasks like this can be.
As our pickle mascot will tell you, Dilligencer combines traditional technology diligence capabilities with a data science platform and proprietary data. One of the notable types of “proprietary” data is built from open source software repositories like PyPI. While simply archiving source code doesn’t make proprietary data, we have enriched information from repos like PyPI, CRAN, and NPM with additional metadata and analysis.
Like our competitors, we have a lot of this kind of data. But unlike our competitors, we don’t serve this data up through a web app or CI hook. Instead, we primarily access and analyze this data through data science pipelines and workflows like Jupyter. This approach gives us the ability to answer the same questions, but with flexibility to customize analysis or move faster than their SaaS hyperscale business models can support.
So, what does SCA look like inside of a data science platform? Let’s take a look.
Our challenge is two-fold. First, we need to identify C and C++ source files that are vendored through PyPI. Second, we need to inspect each of these source files for security issues using a static analysis tool.
To solve the first problem, there are a variety of approaches. For the highest recall, we could utilize a machine learning model. Like natural language processing (NLP) traditionally used for written text in English or other languages, we can apply token or character sequence modeling techniques to detect the *programming* language of a document. We have trained such models for a variety of tasks, including detection of natural language and programming language.
In this case, C and C++ compilers thankfully simplify our task. Whereas other languages may be less picky in their accepted extensions, most C/C++ compilers and build frameworks rely on a small set of acceptable extensions like .h or .cxx. As a result, we can start by searching our PyPI data for any project files that have a matching extension like .c or .h.
Our data model is stored in a large Postgres data store and for many of our use cases, we utilize a simple data access layer built on SQLAlchemy. We can also query using SQLAlchemy’s native approaches too, as demonstrated in the Jupyter notebook.

At this point, we have now identified all projects in PyPI that contain at least one c, cc, or cpp file. We’ll save a few other extensions like cxx or ii for another post.
Next, let’s imagine that we want to iterate through every file from every release from every affected project to determine when the vulnerability was introduced. This takes us just a few lines using our platform distribution access layer, which abstracts away the complexity of retrieving and parsing the structure of each ZIP or tar file.
Next, we can check each file’s extension and, if it matches our C/C++ filter, check it for security vulnerabilities.
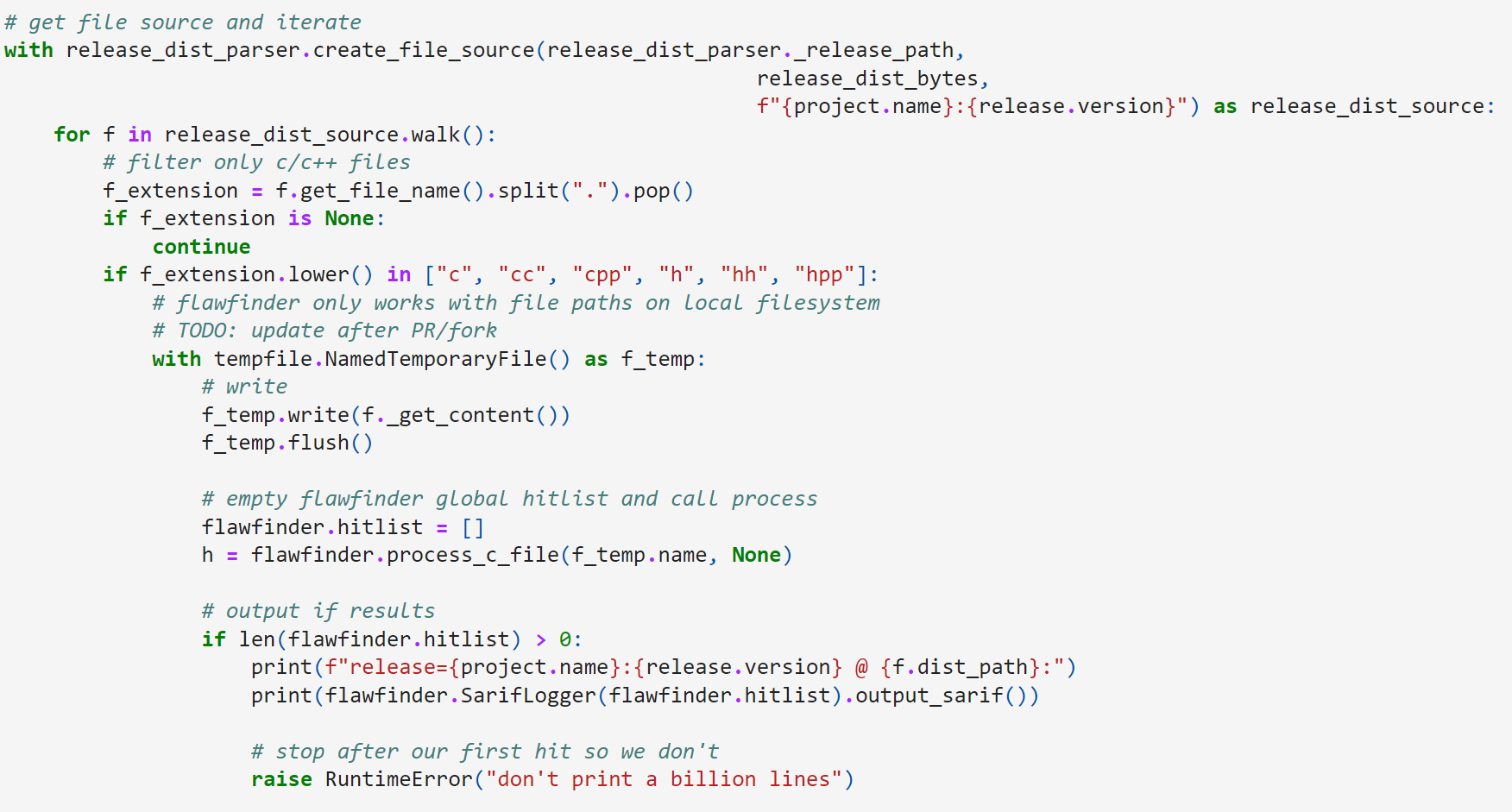
Our second problem is now to run a static analysis tool on each C/C++ file to extract results. For this situation, the tool should be able to operate outside of a build environment, and ideally, even in the presence of some syntax errors. This will allow us to see when vulnerabilities were first introduced into code. Finally, while Dilligencer can easily interact with CLI commands or create microservice wrappers, it would be simplest if the static analysis tool were itself written in Python. The tool that fits this post’s criteria is flawfinder, which unlike other options, is both written in Python and durable against minor syntax errors. Its biggest drawback is that it does not support parsing files via streams or by passing buffers directly to its functions, so we need to create temporary named files for flawfinder to execute.
After navigating this limitation and dealing with its BASIC-inspired globals approach, we finally output results in OASIS’s Static Analysis Results Interchange Format (SARIF).

So, there we have it – static analysis security findings across all C/C++ code in PyPI – and it barely took 40 lines. If you wanted to look at C/C++ code in other languages like R or Node, the code is almost identical. Just swap the repository and dist parser and run again.
You can view the whole Jupyter notebook on GitHub here.
As you can see, a diligence platform inspired by data science patterns can allow experienced analysts to tackle complex problems quickly. Whereas traditional product development patterns would have required days to months of planning, development, testing, and release, we were able to produce this example in just an hour.
While products are nice when your problems are identical and slow-moving, data science platforms allow users to adapt to ever-changing challenges on tight deadlines. That’s why we think platforms are the future of forensics and diligence.
Want to learn more about Dilligencer?
Head on over to https://dilligencer.io and sign up for the mailing list.





